
Introduction
Many automation platforms start with a single-node architecture. One process serves the UI, executes jobs, manages schedules, and handles real-time updates. While this setup is simple, it also creates a single point of failure. If that process stops, automation stops as well.
For organizations running large-scale infrastructure automation — especially in DevOps or platform engineering environments — downtime of the automation system can become a serious operational risk.
This is where Active-Active High Availability (HA) comes in. Semaphore UI supports an architecture where multiple instances run simultaneously and share the workload. This ensures that automation continues even if individual nodes fail, while also enabling horizontal scaling.
The Problem with Single-Node Automation
In a standard deployment, one Semaphore UI process performs all core responsibilities:
- Serves the web UI
- Handles API requests
- Executes scheduled jobs
- Runs automation tasks
- Sends real-time updates to the browser
This architecture works well for small teams or testing environments. However, it introduces a critical limitation. If the single process goes down, the entire system becomes unavailable. For production environments with many users and automated workflows, this creates risks such as:
- Interrupted deployments
- Failed scheduled jobs
- Loss of operational visibility
- Downtime during maintenance
To eliminate this bottleneck, Semaphore UI supports active-active high availability deployments.
What Is Active-Active HA in Semaphore UI?
In an active-active HA architecture, multiple identical Semaphore UI instances run simultaneously behind a load balancer. Unlike traditional failover systems, there is no primary or standby node. Every instance is fully capable of handling UI requests, API calls, scheduled jobs and task execution.
Traffic is distributed across the cluster, and if one instance fails, the others continue serving requests without interruption. This architecture improves both system reliability and execution scalability.
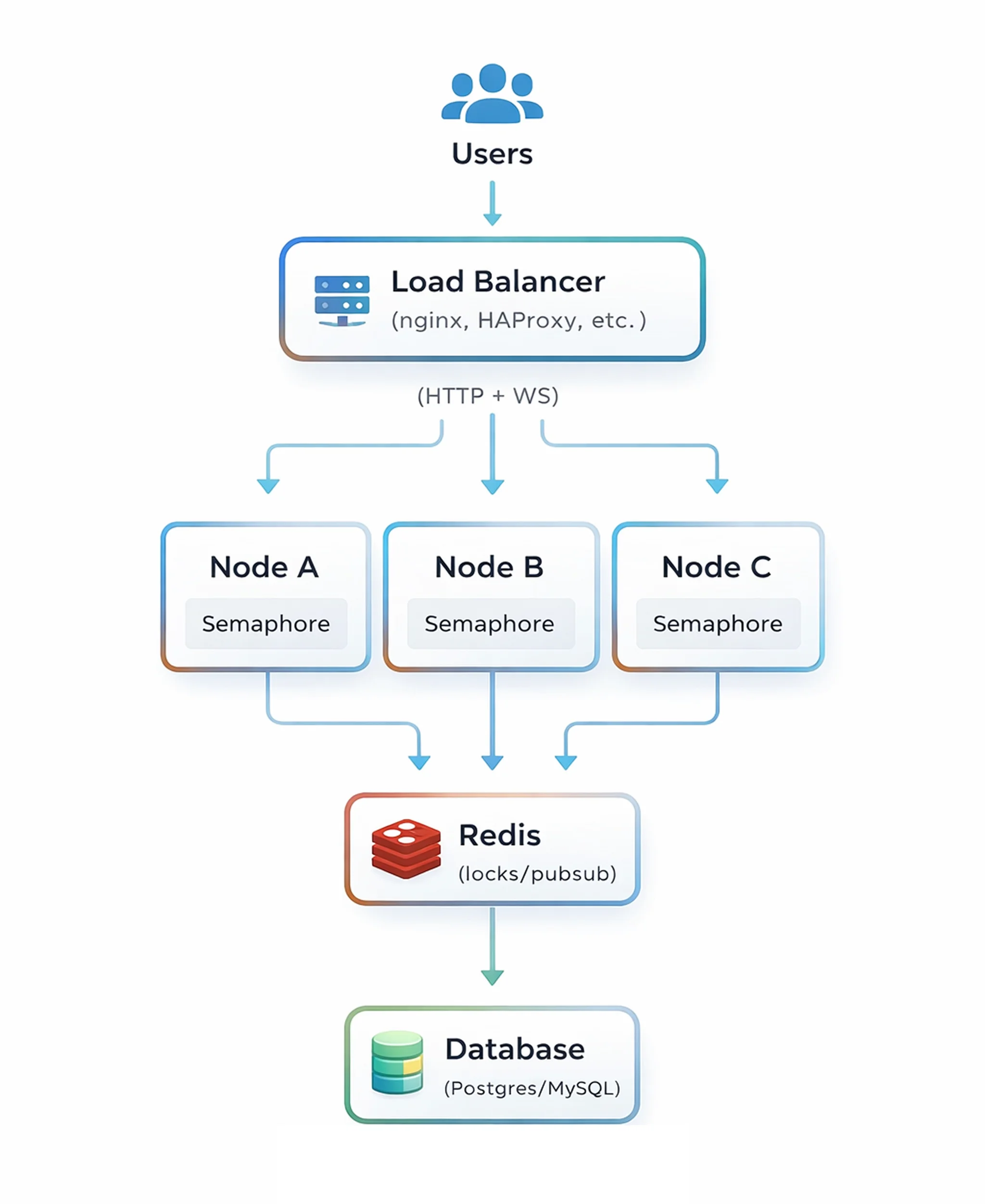
High-Level Architecture
A typical active-active deployment consists of several key components.
-
Load Balancer. Users connect through a load balancer such as NGINX, HAProxy and cloud load balancers. The load balancer distributes HTTP and WebSocket traffic across available Semaphore nodes.
-
Semaphore Nodes. Each node runs an identical instance of Semaphore UI. Any node can receive user requests, start automation jobs, process scheduled tasks, and send real-time updates. Because all nodes are equal, the system has no single point of failure at the application layer.
-
Shared Database. All instances connect to a shared database like PostgreSQL or MySQL. The database acts as the single source of truth for persistent data, including: projects, templates, inventories, schedules, task history, user accounts and RBAC configuration.
-
Redis Coordination Layer. Redis provides the coordination layer that allows multiple nodes to behave as a single system. It serves three important functions.
- Distributed Locks ensure that only one instance executes a job or step at a time. Without distributed locking, multiple nodes might attempt to run the same task simultaneously.
- Shared Task Queue State. Redis maintains the task queue so that jobs are picked up by exactly one worker. All nodes see the same queue and coordinate task execution.
- Pub/Sub Messaging allows nodes to broadcast events such as: task updates, cluster notifications, cache invalidation, UI state updates. This keeps all nodes synchronized in real time.
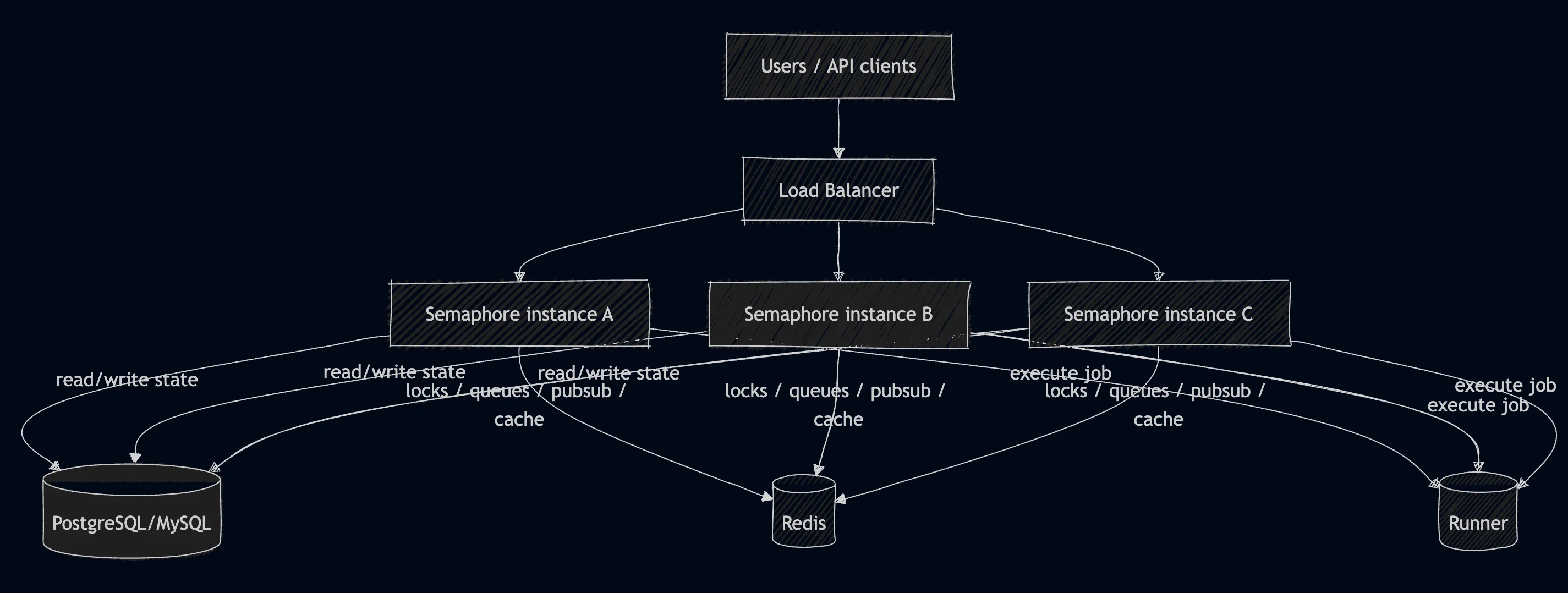
How Job Execution Works in an HA Cluster
In a multi-node Semaphore deployment, task execution follows a coordinated flow.
- A User Triggers a Task. A user starts a job through the UI or API. The request can land on any Semaphore instance.
- Task Metadata Is Stored. The receiving node writes task metadata to the database and signals work through Redis.
- A Node Picks the Task. One of the available nodes retrieves the task from Redis, acquires a distributed lock, and marks the task as running in the database
- The Task Executes. The node executes the task locally, or via distributed runners / agents. Progress and logs are continuously written back to the database.
- Results Are Broadcast. Task updates propagate through Redis Pub/Sub so all nodes and UI clients remain synchronized.
Horizontal Scaling with Multiple Runners
High availability also enables horizontal scaling of task execution. Instead of running jobs only on the Semaphore nodes themselves, execution can be delegated to multiple runners or agents. For large DevOps teams, this architecture supports enterprise-scale automation workloads:
- distribute workload across infrastructure
- scale automation capacity
- isolate execution environments to limit blast radius
- run thousands of nodes in parallel
Benefits of Active-Active Semaphore Deployment
Improved Reliability. If one instance fails, others continue serving traffic and executing jobs.
Zero-Downtime Maintenance. Nodes can be updated or restarted without stopping the system.
Horizontal Scalability. Additional Semaphore nodes can be added behind the load balancer to increase capacity.
No Primary Node Dependency. All nodes are equal, removing complex failover mechanisms. Consistent State Across the Cluster. Shared database storage and Redis coordination keep all instances synchronized.
Typical Use Cases
Active-active Semaphore deployments are common in environments that require continuous automation availability, such as:
- Large DevOps Teams. In organizations where many engineers trigger automation tasks throughout the day, multiple Semaphore instances allow jobs and requests to be processed in parallel, preventing a single node from becoming a bottleneck.
- Enterprise Infrastructure. Companies managing large fleets of servers, virtual machines, or containers rely heavily on automation for configuration and maintenance. High availability helps ensure that critical automation workflows remain operational.
- CI/CD Automation. When Semaphore is used as part of CI/CD pipelines, interruptions can delay deployments and releases. Active-active deployments help keep pipelines running reliably even if individual nodes restart or fail.
- Platform Engineering. Platform teams often use Semaphore as part of internal developer platforms that provide self-service automation. High availability ensures these internal services remain stable and responsive for development teams.
Conclusion
Active-active high availability allows Semaphore UI to evolve from a single automation server into a resilient distributed system. Instead of relying on one process to handle the UI, scheduling, and task execution, multiple Semaphore instances work together behind a load balancer while sharing state through a database and Redis. The result is an automation platform that remains available even when individual nodes fail and can scale horizontally as the workload grows.
Support for active-active HA is available in the Semaphore Enterprise edition. In addition to high availability, the Enterprise version includes capabilities designed for larger teams and production environments — such as advanced RBAC (role-based access control), which allows organizations to define granular permissions across projects, teams, and environments.
If you are evaluating a high-availability automation platform for your infrastructure, you can request a trial of the Enterprise edition to test the HA architecture and see how it fits into your DevOps workflows.
Frequently asked questions
How HA works with Redis, shared databases, node failure, and horizontal scaling.
What is active-active high availability?
Active-active high availability means multiple application instances run simultaneously, and all of them can serve requests. There is no primary node — any instance can handle traffic and execute jobs.
Why does Semaphore use Redis in HA mode?
Redis acts as a coordination layer between instances. It provides distributed locks, shared task queue state, and Pub/Sub messaging to ensure nodes do not execute the same job simultaneously.
What database does Semaphore support for HA deployments?
Semaphore supports PostgreSQL and MySQL as the shared database for storing persistent system data.
What happens if one Semaphore node fails?
The load balancer simply routes traffic to the remaining nodes. Running jobs continue, and new jobs are picked up by other instances.
Can Semaphore scale horizontally?
Yes. Additional Semaphore nodes and runners can be added to increase execution capacity and handle larger automation workloads.


