
Semaphore v2.17 introduit de nouvelles fonctionnalités et des améliorations pour l’automatisation de l’infrastructure et les équipes DevOps. Cette version se concentre sur l’amélioration de l’expérience développeur et la simplification des workflows d’infrastructure-as-code.
Fonctionnalités
Nom d’émetteur personnalisé dans l’application TOTP
Semaphore v2.17 introduit une nouvelle option permettant de personnaliser le nom d’émetteur affiché dans les applications d’authentification TOTP (Time-based One-Time Password).
But :
Le nom d’émetteur aide les utilisateurs à identifier quel compte dans leur application d’authentification appartient à Semaphore, particulièrement utile lorsqu’on gère des comptes de plusieurs organisations ou environnements.
Comment configurer :
Vous pouvez définir le nom d’émetteur de deux manières :
-
Variable d’environnement
Définissez la variable d’environnement
SEMAPHORE_TOTP_ISSUERsur le nom d’émetteur souhaité au démarrage de Semaphore.Exemple (Docker Compose) :
environment: - SEMAPHORE_TOTP_ISSUER=MyCompany SemaphoreExemple (Standalone) :
SEMAPHORE_TOTP_ISSUER="MyCompany Semaphore" ./semaphore server -
Fichier de configuration
Dans votre fichier
config.json, définissez l’option suivante dans la sectionauth:{ "auth": { "totp": { "issuer": "MyCompany Semaphore" } } }
Priorité :
Si la variable d’environnement et l’option du fichier de configuration sont toutes deux définies, la variable d’environnement (SEMAPHORE_TOTP_ISSUER) a la priorité.
Valeur par défaut :
Si elle n’est pas définie, le nom d’émetteur par défaut sera Semaphore.
Résultat :
Lorsque les utilisateurs ajoutent leur compte TOTP Semaphore à une application d’authentification, le nom d’émetteur sélectionné s’affichera, facilitant la distinction entre plusieurs comptes.
Pour tous les détails sur l’ensemble des variables d’environnement disponibles, voir la documentation sur les variables d’environnement d’installation.
Tâches planifiées une seule fois
Semaphore prend désormais en charge les schedules à exécution unique en plus des schedules cron. Utilisez cela lorsque vous devez qu’une tâche s’exécute à une date et une heure précises et ne s’exécute qu’une seule fois.
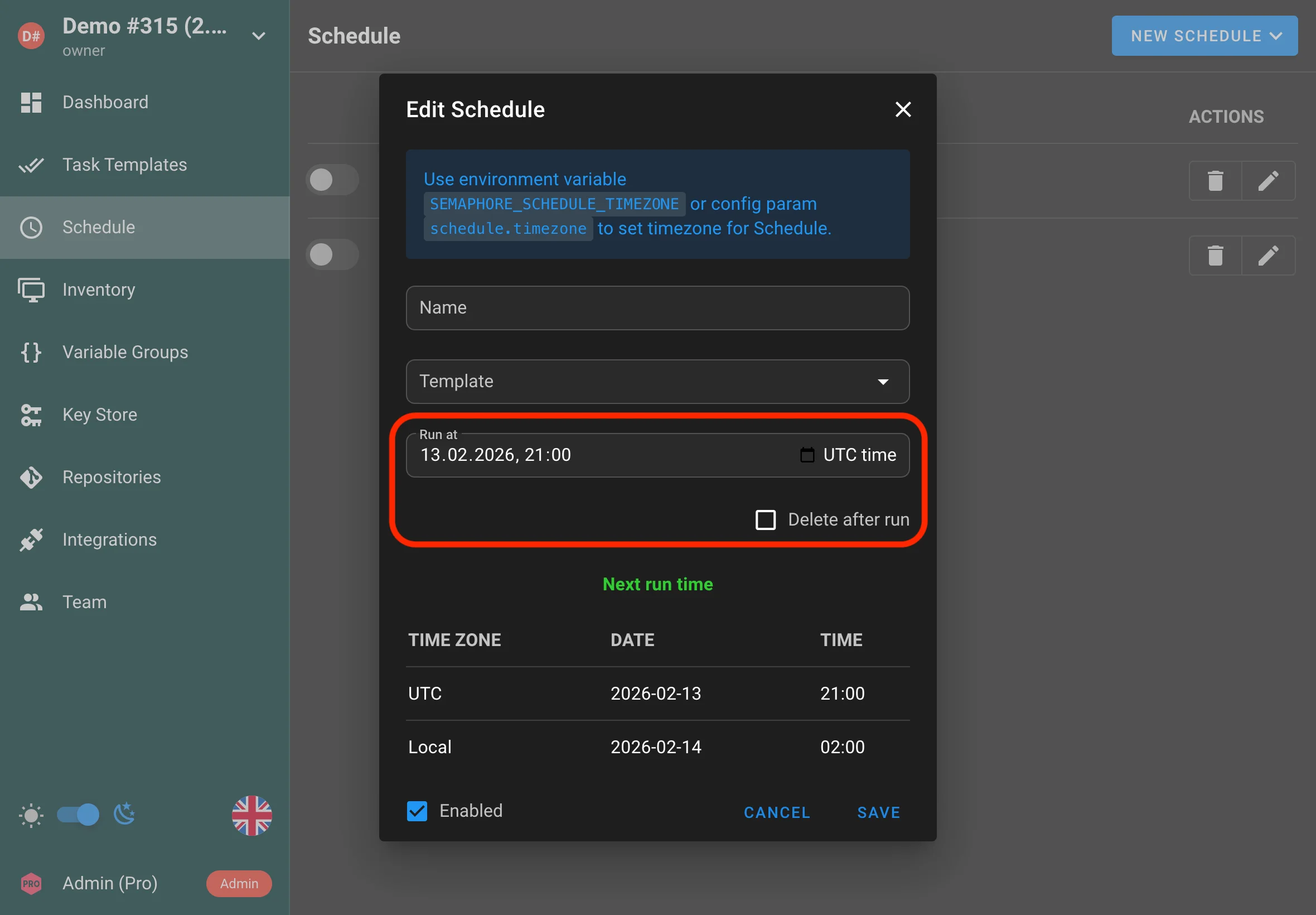
Cas d’utilisation :
- Exécuter une tâche de maintenance pendant une fenêtre de changement approuvée
- Lancer un déploiement ponctuel ou un job de backfill
Vues personnalisables
Les vues des templates sont désormais plus personnalisables, ce qui vous permet d’adapter ce qui est affiché et la manière dont c’est organisé pour mieux correspondre à votre flux de travail.
-
Vous pouvez désormais déplacer l’onglet All à n’importe quel endroit dans la barre.
-
Vous pouvez masquer entièrement l’onglet All aux utilisateurs réguliers du projet.
-
Vous pouvez modifier le tri par défaut des templates pour une vue spécifique.
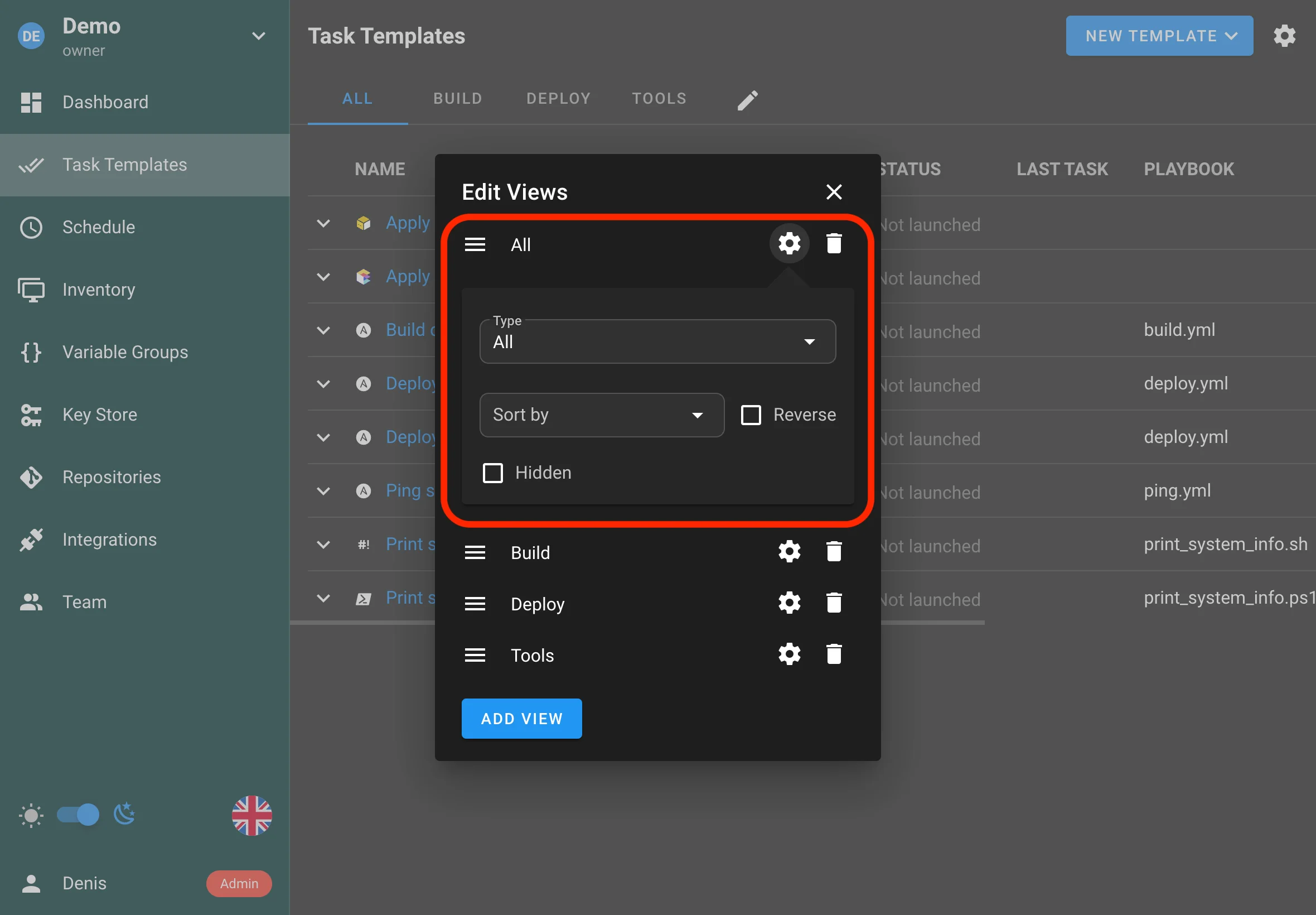
Améliorations typiques :
- Meilleure organisation des informations liées aux templates
- Plus de flexibilité dans l’agencement du contenu des vues
Arrêter toutes les tâches
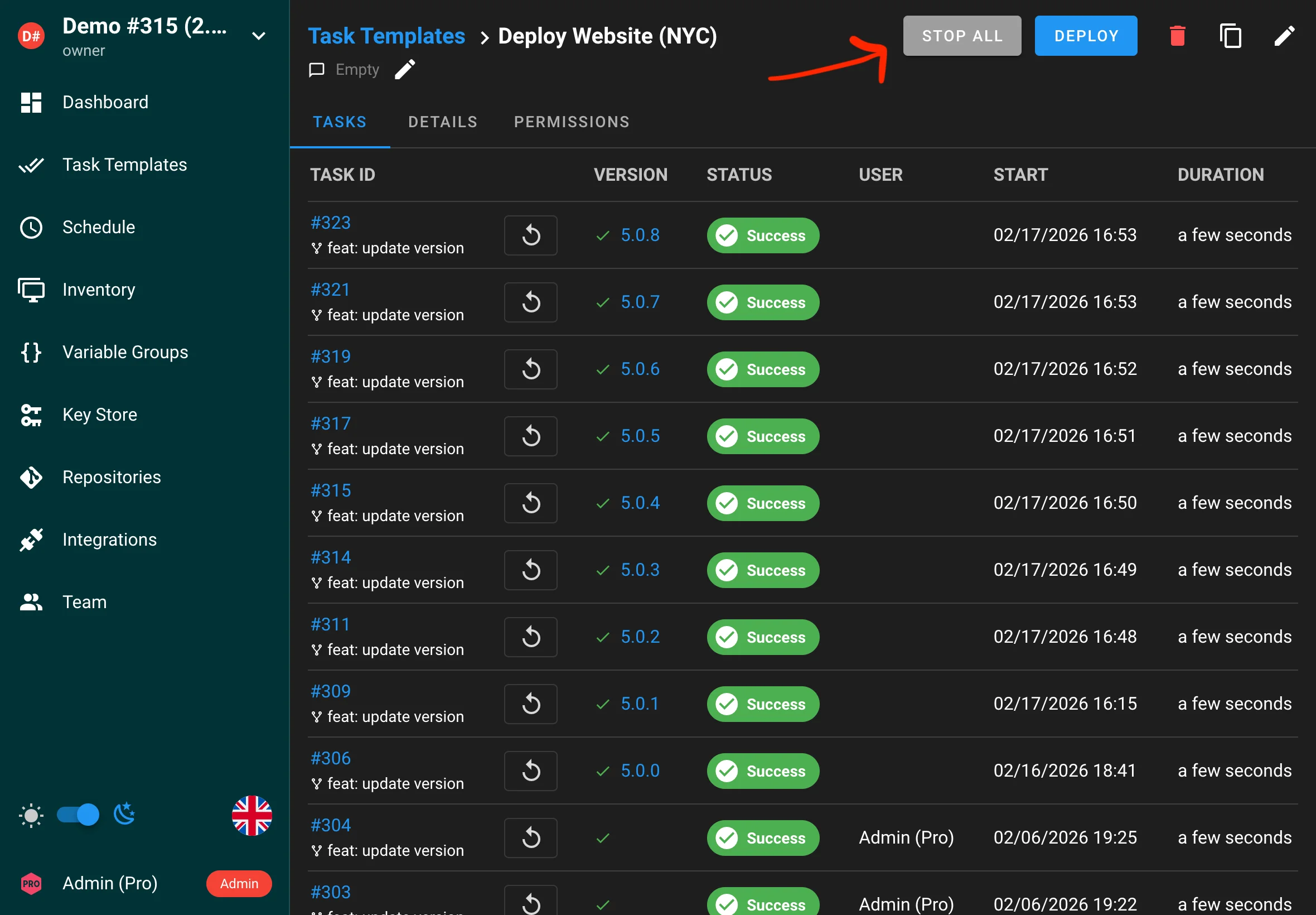
Vous pouvez désormais arrêter toutes les tâches en cours pour un template en une seule action. Cela vous aide à interrompre rapidement un déploiement ou à annuler des jobs lancés par erreur.
Support du serveur Syslog
Semaphore peut désormais transférer les logs vers un serveur syslog externe, facilitant la centralisation de la collecte des logs et l’intégration avec les pipelines de monitoring et d’alerte existants.
config.json:
{
"syslog": {
"enabled": true,
"network": "udp",
"address": "localhost:514",
"tag": "semaphore"
}
}
Variables d’environnement :
export SEMAPHORE_SYSLOG_ENABLED=True
export SEMAPHORE_SYSLOG_NETWORK=udp
export SEMAPHORE_SYSLOG_ADDRESS=localhost:514
export SEMAPHORE_SYSLOG_TAG=semaphore
Rollback des migrations de base de données
Les migrations de base de données peuvent désormais être annulées (rollback). Cela rend la récupération après un problème de mise à jour plus sûre et peut simplifier les rétrogradations lorsque nécessaire.
semaphore migrate --undo-to 2.16
Glisser-déposer pour les variables de survey, les arguments CLI, etc.
Vous pouvez désormais réordonner les variables de survey, les arguments CLI et autres éléments de liste via glisser-déposer, ce qui rend les templates plus faciles à maintenir et à relire.
Export et import de projets via la CLI
Semaphore prend désormais en charge l’import automatique de projets.
Le conteneur Docker accepte pour cela les variables d’environnement SEMAPHORE_IMPORT_PROJECT_FILE et SEMAPHORE_IMPORT_PROJECT_NAME.
Si vous devez importer un projet via la CLI, vous pouvez utiliser la commande suivante :
semaphore project import --file /path/to/the/backup.json --project-name "Demo project"
Si le nom du projet n’est pas fourni, le nom du projet issu des métadonnées de la sauvegarde sera utilisé.
Pour importer tous les projets depuis un répertoire, utilisez la commande suivante :
semaphore project import --dir /path/to/the/dir
Pour exporter un projet, vous pouvez utiliser la commande suivante :
semaphore project export --project-name "Demo project" --file /path/to/the/backup.json
Si vous souhaitez exporter tous les projets vers un répertoire :
semaphore project export --dir /path/to/the/dir
En combinant cette commande avec cron, vous pouvez mettre en place des sauvegardes automatiques de projets.
Outil CLI pour migrer de BoltDB vers SQLite/MySQL/Postgres
Un nouveau migrateur CLI aide à déplacer les données de Semaphore depuis BoltDB vers SQLite, MySQL ou Postgres. BoltDB est en cours de dépréciation et sera supprimé dans la v3.0.
semaphore migrate --from-boltdb /path/to/boltdb/file
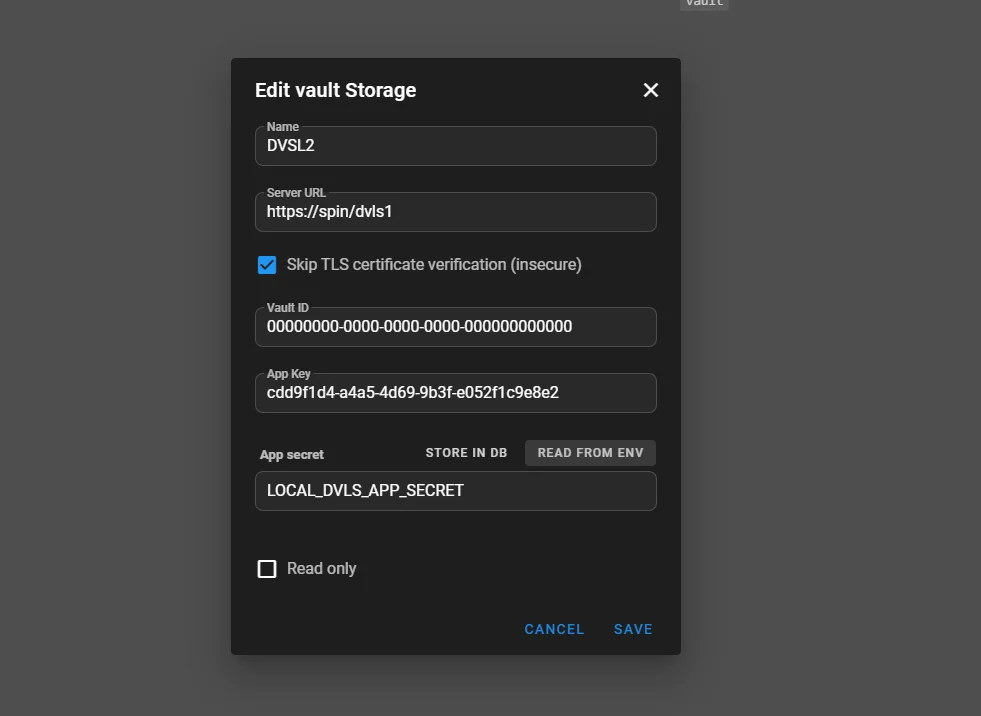
Support Devolutions Server (Enterprise)
Les installations Enterprise peuvent désormais s’intégrer à Devolutions Server comme backend de secrets, similaire à HashiCorp Vault.
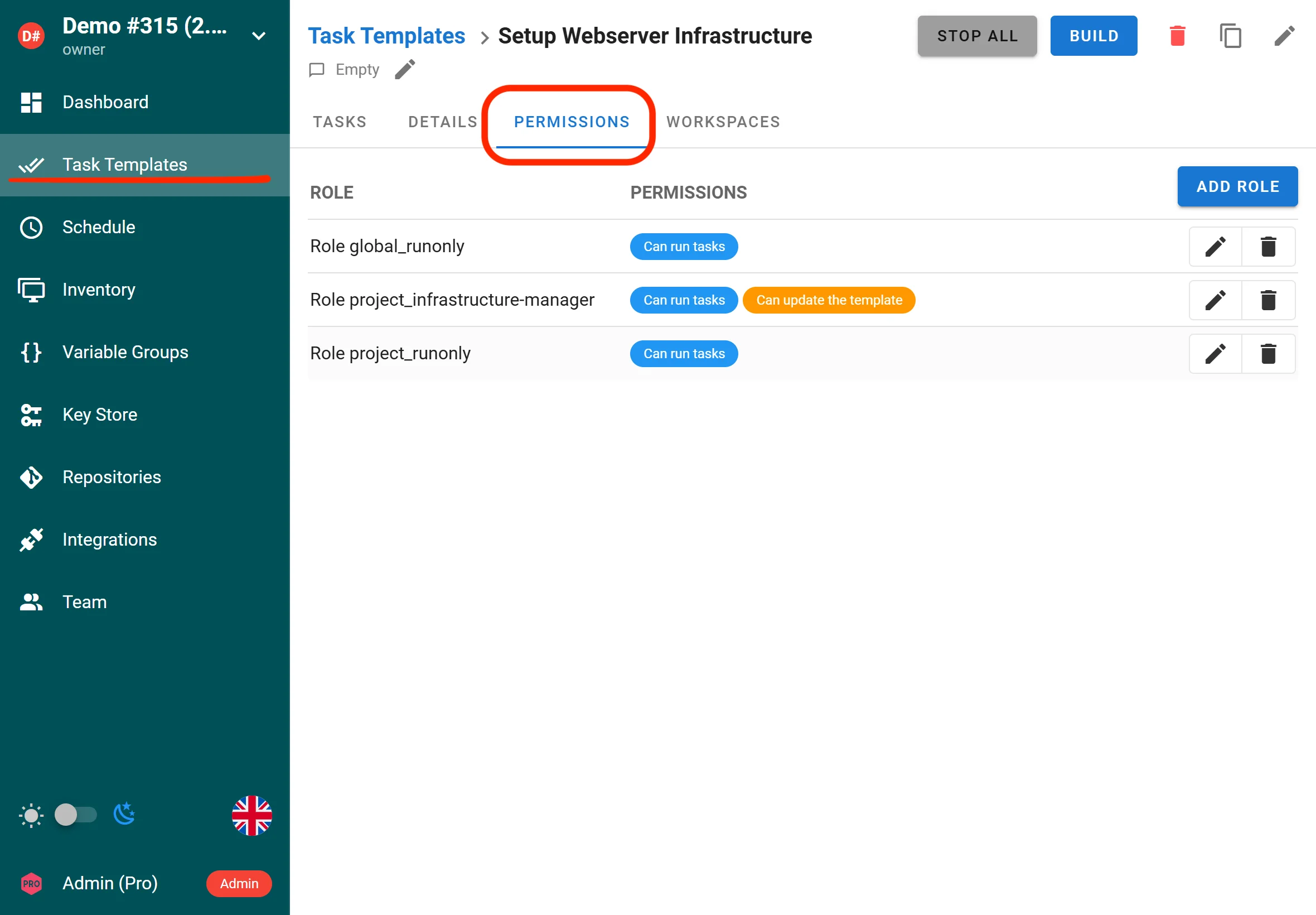
Rôles personnalisés et RBAC étendu (Enterprise)
L’interface de Semaphore prend désormais en charge des rôles personnalisés au niveau du projet et au niveau global, permettant un contrôle d’accès fin pour les tâches et les templates. Le RBAC a été étendu avec des contrôles plus granulaires à travers les ressources Semaphore, aidant les équipes à appliquer le principe du moindre privilège de manière plus précise.
Les utilisateurs Enterprise peuvent définir des rôles personnalisés avec des permissions adaptées aux besoins d’accès de leur organisation.
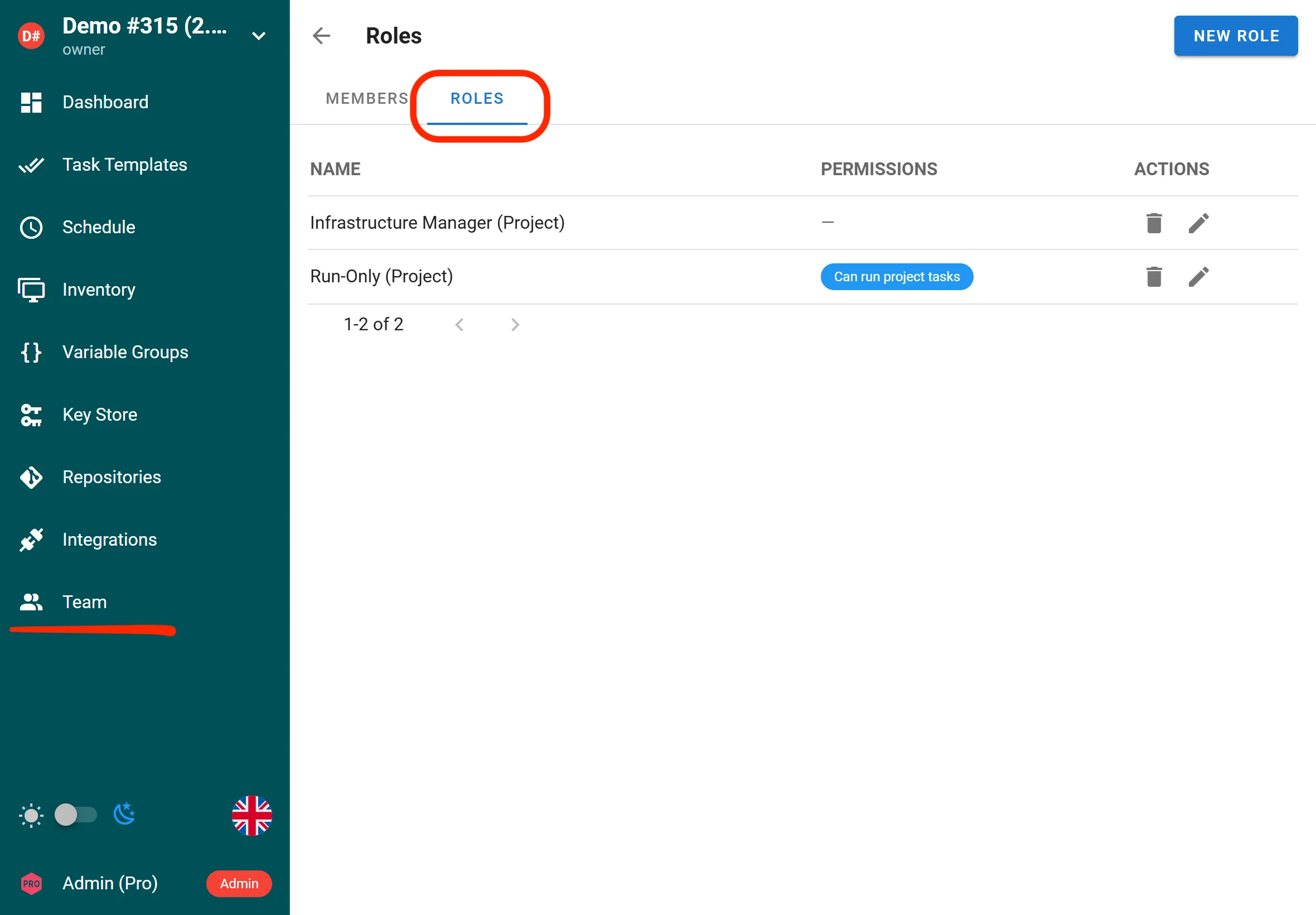
Les propriétaires et managers de projet peuvent assigner ces rôles à des templates spécifiques et leur donner des permissions ciblées pour exécuter, consulter ou gérer des tâches.
Haute disponibilité active-active (Enterprise)
Dans une configuration standard à un seul nœud, un processus Semaphore fait tout : il sert l’UI web, exécute les jobs planifiés, exécute des tâches et pousse des mises à jour en direct vers les navigateurs. Si ce processus tombe, tout s’arrête.
Avec la HA active-active, vous exécutez plusieurs instances Semaphore identiques derrière un load balancer. Elles sont toutes pleinement actives en même temps — il n’y a ni « primaire » ni « standby ». N’importe quel nœud peut servir n’importe quelle requête, exécuter n’importe quelle tâche ou déclencher n’importe quel schedule. Elles se coordonnent via une instance Redis partagée pour éviter de se marcher dessus.
Toutes les instances se connectent aux deux mêmes backends :
- Base de données (Postgres ou MySQL) — la source de vérité unique pour toutes les données persistantes : projets, templates, schedules, historique des tâches, utilisateurs, etc.
- Redis — la couche de coordination. Redis a trois rôles :
- Verrous distribués — pour empêcher deux nœuds d’exécuter la même chose
- Messagerie Pub/Sub — pour relayer les événements en temps réel entre nœuds
- État partagé de la file de tâches — pour que tous les nœuds voient la même file
{
"ha": {
"enabled": true,
"node_id": "node1",
"redis": {
"addr": "localhost:6379"
}
}
}
Journalisation améliorée
La journalisation a été améliorée pour fournir plus de contexte et de clarté, vous aidant à diagnostiquer les échecs et à comprendre ce qui s’est passé lors d’une exécution.
Clé d’abonnement via variable d’environnement (PRO)
Les clés d’abonnement PRO peuvent désormais être fournies via une variable d’environnement, ce qui est utile pour les déploiements conteneurisés et les rollouts pilotés par CI/CD.


