Semaphore v2.16 rend la documentation API Swagger intégrée disponible dans la version open source, introduit des paramètres de tâches pour les Schedules et les Integrations, et ajoute le support de SQLite.
Table des matières
-
Fonctionnalités
-
Documentation API Swagger intégrée
Accédez à une documentation API complète directement dans l’interface de Semaphore, permettant une intégration transparente avec des outils externes et des pipelines CI/CD.
En savoir plus » -
Paramètres de tâches pour les Schedules et les Integrations
Définissez et passez des paramètres personnalisés aux tâches déclenchées par les Schedules et les Integrations, permettant des flux de travail d’automatisation plus flexibles et dynamiques.
En savoir plus » -
Support de SQLite
Exécutez Semaphore avec un moteur de base de données léger et basé sur des fichiers pour une configuration plus facile et un développement local.
En savoir plus » -
BoltDB a été déprécié
BoltDB est désormais déprécié au profit de SQLite, offrant une option de base de données plus robuste et maintenable.
En savoir plus » -
Tâches parallèles pour le même Template
Vous pouvez désormais exécuter plusieurs tâches simultanées à partir du même Template, permettant un meilleur débit et une plus grande flexibilité dans vos flux de travail d’automatisation.
En savoir plus » -
Support de HashiCorp Vault (PRO)
En savoir plus »
-
Fonctionnalités
Documentation API Swagger intégrée (PRO)
Les utilisateurs de Semaphore peuvent désormais accéder à une documentation API complète via une interface Swagger UI intégrée. Cette fonctionnalité puissante permet aux équipes DevOps de :
- Parcourir et explorer tous les points de terminaison API disponibles
- Voir les spécifications détaillées des paramètres et des formats de réponse
- Exécuter des requêtes de test directement depuis l’interface
- Rationaliser l’intégration avec des outils externes et des pipelines CI/CD
- Accélérer le développement de solutions d’automatisation personnalisées
La documentation Swagger intégrée facilite plus que jamais l’intégration de Semaphore avec votre chaîne d’outils DevOps existante et vos flux de travail d’automatisation personnalisés.

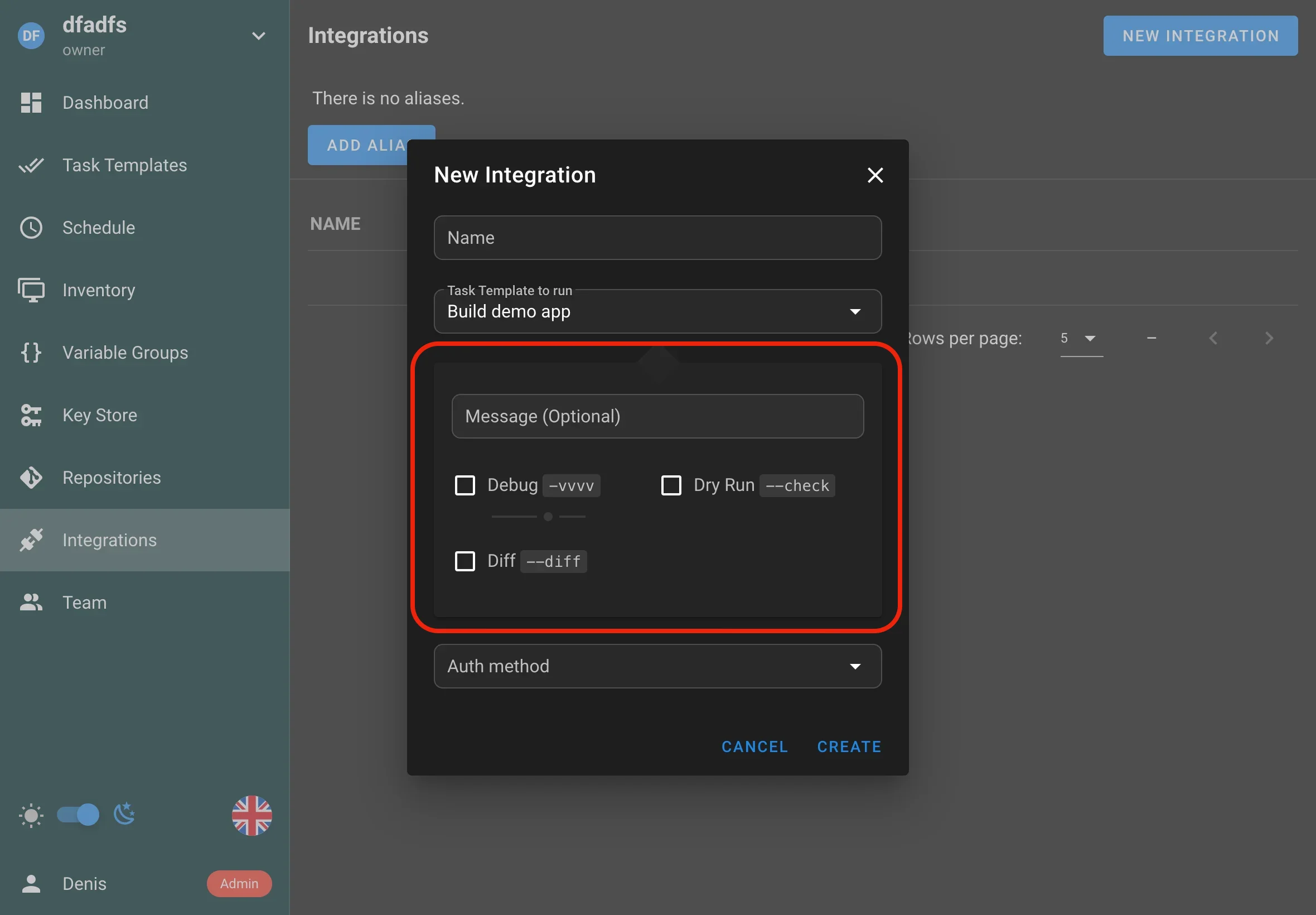
Paramètres de tâches pour les Schedules et les Integrations
Semaphore permet désormais de définir et de passer des paramètres aux tâches exécutées via les Schedules et les Integrations. Cette amélioration apporte toute la puissance des paramètres de tâches à chaque point d’entrée d’automatisation dans Semaphore, vous permettant de :
- Injecter des variables telles que des noms d’environnement, des branches Git ou des drapeaux de fonctionnalités directement dans vos playbooks Ansible et vos plans Terraform.
- Réutiliser les mêmes templates dans plusieurs scénarios sans dupliquer le code.
- Construire des flux de travail dynamiques et contextuels qui s’adaptent à la manière dont ils sont déclenchés.
Support de SQLite
Semaphore prend désormais en charge l’utilisation de SQLite comme moteur de base de données. Cette option légère et basée sur des fichiers facilite considérablement la mise en route de Semaphore dans des environnements où la gestion d’une instance PostgreSQL externe est excessive.
Les principaux avantages incluent :
- Aucune dépendance externe – tout est stocké dans un seul fichier
.sqlitequi vit aux côtés de l’application. - Idéal pour le développement local et les petites équipes – déployez une instance complète de Semaphore sur un ordinateur portable ou dans CI sans services supplémentaires.
- Configuration rapide dans des environnements conteneurisés et en périphérie – parfait pour des démonstrations, des déploiements de PoC et des environnements de test éphémères.
- Chemin de migration sans faille – commencez avec SQLite et passez à PostgreSQL plus tard en utilisant les commandes d’exportation/importation intégrées.
BoltDB a été déprécié
BoltDB a servi de magasin de clés-valeurs intégré pour Semaphore depuis ses premières versions. À partir de la version v2.16, il est officiellement déprécié et sera supprimé dans une future version majeure.
Pourquoi ce changement ?
- Limitation d’un seul écrivain – BoltDB permet uniquement un écrivain concurrent, ce qui limite la scalabilité sur des installations chargées.
- Friction de migration – l’évolution des structures de données nécessite un code d’application sur mesure.
SQLite remplace désormais BoltDB en tant que moteur de stockage par défaut (voir la section Support de SQLite).
Impact sur les utilisateurs existants
- Les installations actuelles de BoltDB continuent de fonctionner, mais aucune nouvelle fonctionnalité ne sera testée contre Bolt.
- Les nouvelles installations par défaut à SQLite ne peuvent plus créer de nouvelles bases de données BoltDB.
- Le support officiel pour BoltDB sera interrompu environ 6 mois après cette version.
- Un script de migration sera bientôt disponible.
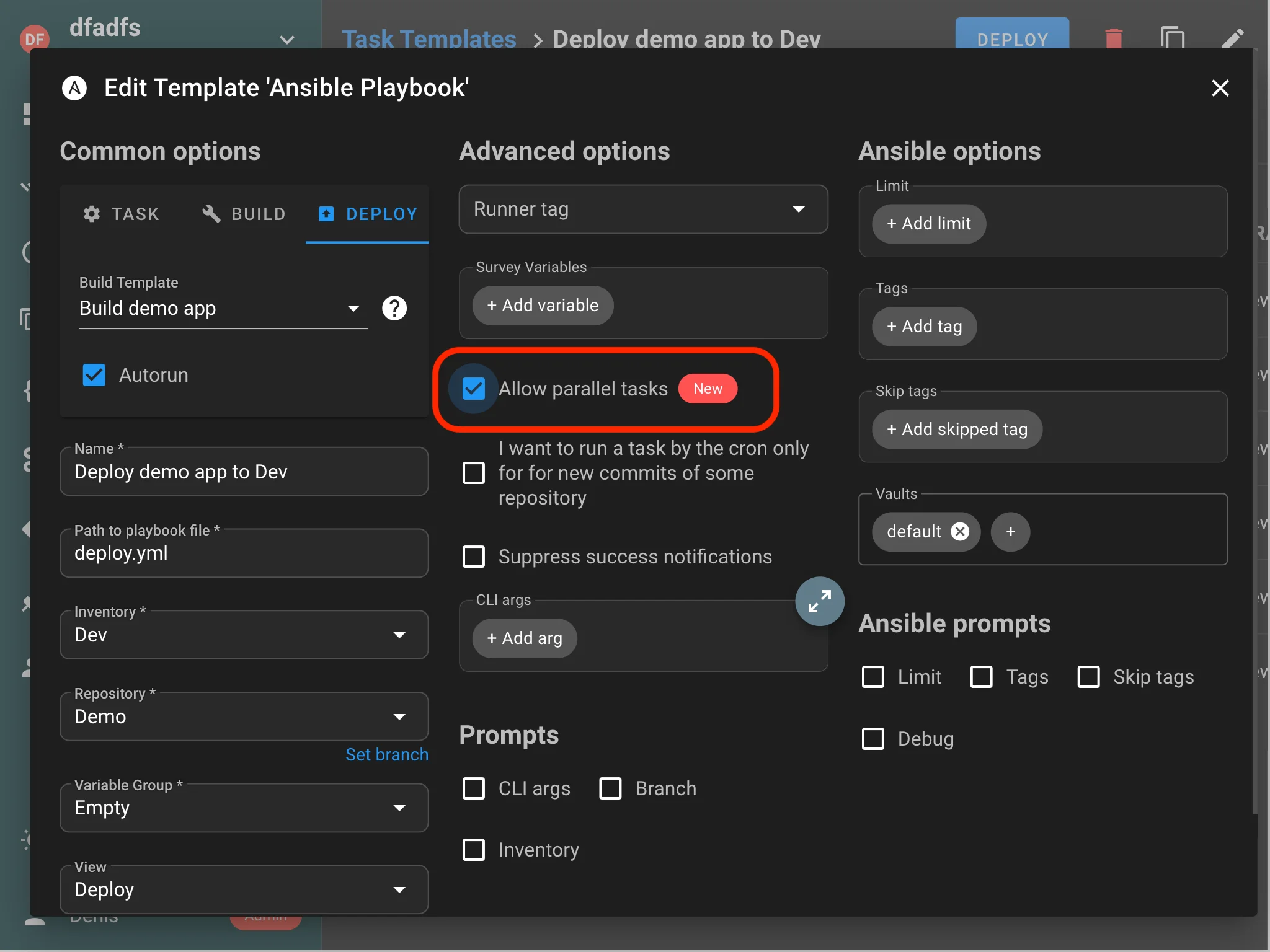
Tâches parallèles pour le même Template
Semaphore permet désormais d’exécuter plusieurs tâches simultanées à partir du même template, améliorant considérablement le débit pour les flux de travail d’automatisation à forte demande. Par défaut, les tâches du même template sont mises en file d’attente séquentiellement pour éviter les conflits de ressources et garantir un ordre d’exécution prévisible.
Comment cela fonctionne :
- Exécution séquentielle (par défaut) : Les tâches du même template sont mises en file d’attente et exécutées les unes après les autres, évitant les conflits de ressources et maintenant un ordre d’exécution prévisible.
- Exécution parallèle : Activez la case à cocher “Autoriser les tâches parallèles” dans les paramètres du template pour exécuter plusieurs instances du même template simultanément.
Cette fonctionnalité est particulièrement utile pour des scénarios tels que les déploiements progressifs, les mises à jour d’environnement parallèles, ou lorsque plusieurs développeurs doivent exécuter le même flux de travail d’automatisation simultanément.
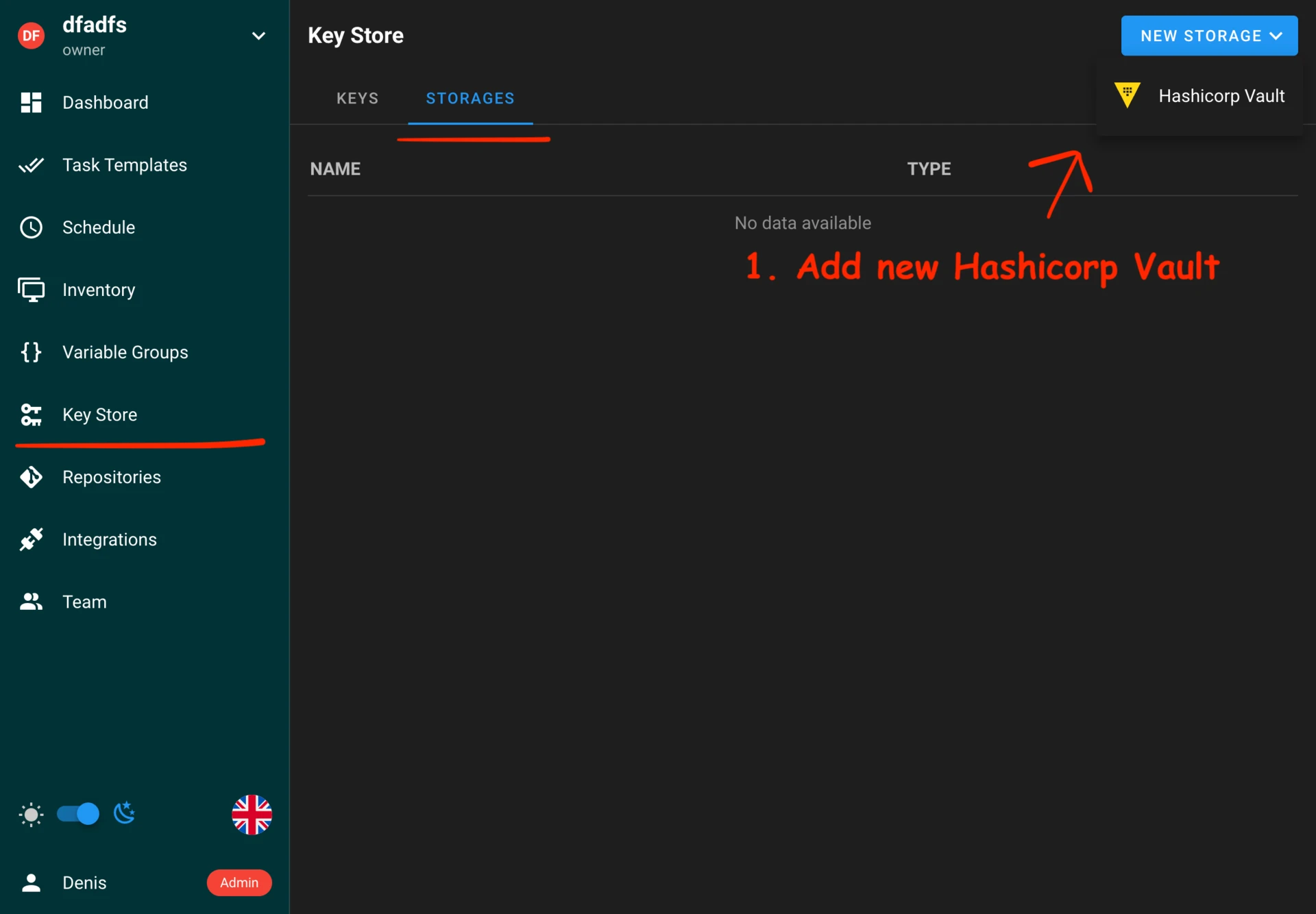
Support de HashiCorp Vault (PRO)
Semaphore propose désormais une intégration native avec HashiCorp Vault pour la gestion sécurisée des clés. Lors de la création ou de la mise à jour d’un secret dans l’interface Semaphore, vous pouvez choisir de le stocker dans la base de données intégrée ou dans votre instance Vault. Cela vous donne la flexibilité de gérer des informations d’identification sensibles selon vos exigences de sécurité et votre infrastructure existante.
Principaux avantages :
- Stockage flexible : Sélectionnez au cas par cas si vous souhaitez stocker les informations d’identification dans la base de données Semaphore ou dans Vault.
- Sécurité améliorée : Les secrets stockés dans Vault ne résident jamais dans la base de données Semaphore et ne sont accessibles que lorsque cela est nécessaire.
- Gestion centralisée : Utilisez les outils de Vault pour gérer, faire tourner et auditer les secrets stockés à l’extérieur.
- Intégration transparente : Connectez facilement Semaphore à votre déploiement Vault existant avec une configuration minimale.
- Contrôle d’accès : Profitez des politiques granulaires de Vault pour contrôler quels utilisateurs et projets peuvent accéder à des secrets spécifiques.
Cette fonctionnalité est disponible dans Semaphore PRO et est idéale pour les organisations ayant des exigences de sécurité strictes ou celles utilisant déjà Vault pour la gestion des secrets.